在数据收集这一块,火车采集器应用挺广,可许多人虽然能收集到网址,却不知道怎么正确引用,这事挺让人烦恼的。
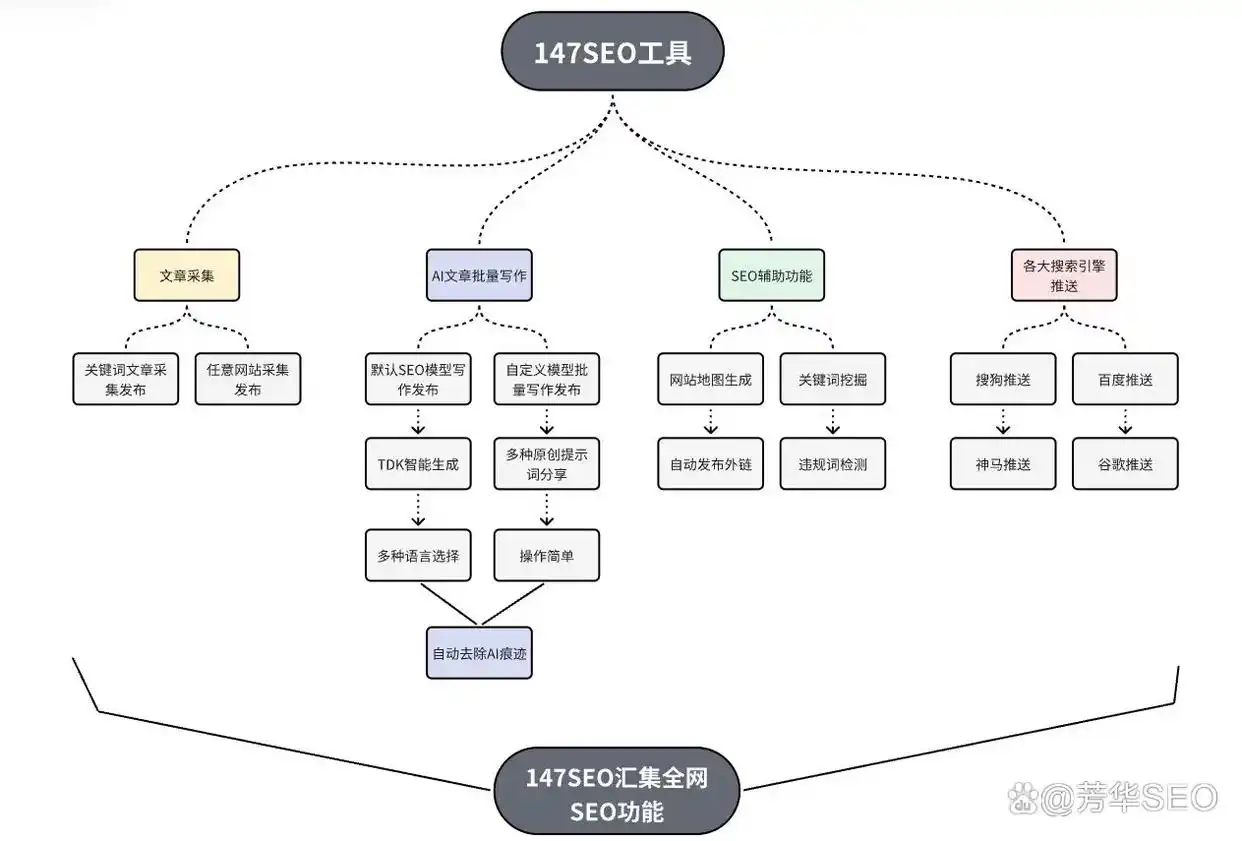
火车采集器与url引用的关系
在互联网数据处理领域,火车采集器扮演着关键角色。众多小型互联网工作室频繁使用它来抓取网页信息。一旦在采集过程中引用url出现错误,可能会对数据链造成不良影响。据2022年的一项小规模调查显示,众多采集员在处理url引用时都感到困难。
火车采集器所获取的url并非仅仅是搜集信息,它实际上是一个深入挖掘数据价值的途径。以电商领域为例,我们能够利用这些采集到的url所指向的商品信息,进行商品分析等一系列操作。
正则表达式入门理解
处理火车采集器收集的网址,正则表达式的作用至关重要。它就好比一套精细的法则。比如,“^”符号就是其中的界定标志,这是最基础的规则。许多初学者对此不太理解,因此在操作时常常出现错误。
字符匹配中,“?”代表可以出现0次或1次。举例来说,当我们从某新闻网站抓取链接时,有些新闻页面并非必需,这时“?”便起到了这种匹配功能。这属于熟练用户的基本技能,但新手们常常需要他人的指导和说明。
火车采集器的标签添加
火车采集器里贴上标签至关重要。举例来说,在搜集内容农场网站资料时,恰当地加上标签能更准确地获取信息。记得有位采集员从2021年起着手料理菜谱网站的数据整理,正是由于标签的精准运用,他的采集工作变得极为高效。
挑选数据来源至关重要,尤其是从网址获取信息这一基本步骤。若对此不甚了解的人选错了,就可能无法获取有效的网址数据。这样的错误对于整个数据搜集过程来说,可能是致命的。
提取方式选正则提取
![图片[1]-火车采集器教程:如何获取并引用采集网址中的URL参数数据-东山笔记](http://83ch.com/47.png)
正则提取并非随意选择。早在多年前,当类似采集器刚出现时,就存在多种提取方法。其中,正则提取在处理复杂的URL结构方面展现出显著优势。尤其是那些具有嵌套结构的网页URL。
操作需按步骤进行,点击相应的图标看似容易,实则其中蕴含着深奥的原理。这种点击行为背后,实际上对应着正则表达式的逻辑。对于不熟悉的人来说,可能会感到困惑,无法正确操作,最终导致无法获取到有用的URL部分。
火车采集器不同版本的操作
V9开心版高铁采集器和V7.6等不同版本的操作,虽有细微差别,但大体相似。在某个采集爱好者的小团队中,成员们各自使用不同的版本进行工作。不过,他们发现,无论是哪个版本,在采集到URL后设置引用参数的基本步骤,其原理都是一致的。
以V7.6版为例,即便它是个旧版本,在处理URL引用的操作配置时,其实质依旧涉及到了正则表达式和相应设置的应用。虽然界面可能有所区别,但操作的基本逻辑保持一致。
保存采集页地址到本地
有时得将网页的地址存入本地文档。这时,我们可以借助[标签:]这样的便捷功能。有位负责建立本地文档知识库的人说,这让他轻松保存了网页链接。
将网页地址存于本地,便于今后查阅和评估,不论是学术探讨还是商业考量。举例来说,研究历史的学者会把收集到的历史资料网址保存在本地,以便之后对相关历史资料进行深入分析。
火车采集器在收集url信息并使其可引用的过程中,有许多细节需要留意。那么,在实际操作中,你是否遇到过觉得特别的问题?期待大家点赞、转发,并在评论区展开讨论。