现今,网络文学异常火爆。起点网的畅销榜单成了众多读者和从业者关注的中心。获取这份榜单的数据显得尤为珍贵。但如何高效、合规地获取、整理这些数据,并妥善保存,对许多人来说是个难题。
了解爬取任务
众多人对数据抓取充满兴趣。我们首先要确定,目标是获取起点小说网的热销榜单数据。这些数据中蕴藏着丰富的信息。例如,通过分析,我们能掌握当前小说的流行走向。无论是小说创作者想要了解竞争对手,还是平台进行自我检查,甚至是对网站进行优化,这些数据都是不可或缺的。
人们使用这些数据的目的各不相同。比如,一位小说网站的编辑发现起点热销榜上某种类型的小说颇受欢迎。于是,在策划自己平台的推荐专题时,他可以借鉴这一信息。例如,2022年就有编辑依据这些数据推出了受欢迎小说的新作专题,反响不错。
安装必要模块
% pip3 install bs4
进行数据抓取,bs4这个模块是关键。安装起来很简单,只需在线使用pip工具。古人云,要做好一件事,先得把工具准备好。就拿小张来说,他初次尝试这个项目,发现只需一条简单的指令就能轻松安装bs4,这样就能把更多时间用在后续更为关键的环节上。
安装了bs4模块,就好比拥有了开启数据宝库的钥匙。已有案例显示,某些团队因忽略了安装模块这一基本环节,最终遇到了不少麻烦。这说明虽然这一步骤看似简单,但绝不可掉以轻心。
网页结构分析
要分析起点小说网的热销榜单,首先得了解网页的构造。浏览网页时,我们要启用浏览器的开发者模式。切换到“文档”标签后,就能发现许多有价值的数据。
举例来说,浏览网页上的小说内容时,其对应的HTML代码就存在于此处。比如,某技术员在研究类似网页时,由于忽略了这一“Doc”标签,导致后续数据抓取出现误差。此外,该标签下的请求地址与浏览器地址栏内容相同。
确定爬取方式
网页抓取方法主要分为两大类。一类是专门针对获取网页加载完毕后的内容,比如当我们需要获取某些页面展示的最新动态信息时。另一类则涉及特定模块,需要借助开发者工具中的不同标签,对网页进行细致分析,以确定相应的请求方式。
根据过往项目经验,若在数据抓取时未选用恰当的方法,可能会造成数据的大量缺失。比如,团队A在抓取某小说排行榜时,由于选择了错误的方法,最终抓取到的数据仅占实际应得数据的60%左右,造成了不小的损失。
动态URL处理
起点小说榜网页设有分页机制。每页都对应一个独特的网址。在这个网址中,参数“page”扮演着关键角色,通过调整这个参数,可以查看不同页码的内容。
以前有过类似的情况,有人在未妥善处理动态网址时尝试抓取数据,结果造成了数据不齐全。例如,只获取了小说的第一页内容。按照正常流程,只需适当调整参数,就能完整地获取所有分页的数据。
数据清洗存储
from bs4 import BeautifulSoup
import aiohttp
import asyncio
import csv
import pandas as pd
from pandas.io.excel import ExcelWriter
# 定义网站访问函数getData,将网站内容返回
async def getData(url, headers):
# 创建会话对象session
async with aiohttp.ClientSession() as session:
# 发送GET请求,并设置请求头
async with session.get(url, headers=headers) as response:
# 返回响应内容
return await response.text()
# 定义存储数据函数,解析页面返回
def saveData(result):
for _ in result:
soup = BeautifulSoup(_, 'html.parser')
find_div = soup.find_all('div', class_='book-mid-info')
for d in find_div:
name = d.find('h2').getText()
author = d.find('a', class_='name').getText()
![图片[1]-如何使用bs4模块爬取起点小说网24小时热销榜数据并存储为CSV文件-东山笔记](https://83ch.com/wp-content/themes/zibll/img/thumbnail-lg.svg)
intro = d.find('p', class_='intro').getText()
update = d.find('p', class_='update').getText()
csvFile = open('data.csv', 'a', newline='')
writer = csv.writer(csvFile)
writer.writerow([name, author, intro, update])
csvFile.close()
# 定义运行函数
def run():
for _ in range(25):
# 构建不同的URL地址并传入函数getData,最后由asyncio模块执行
task = asyncio.ensure_future(getData(url.format(_ + 1), headers))
# 将所有请求加入到列表tasks
tasks.append(task)
# 等待所有请求执行完成,一并返回全部的响应内容
result = loop.run_until_complete(asyncio.gather(*tasks))
saveData(result)
print(len(result))
if __name__ == '__main__':
headers = {
'User-Agent':
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 '
'Safari/537.36 '
}
csvFile = open('data.csv', 'w', newline='')
writer = csv.writer(csvFile)
# 写入标题,以便后面转成电子表格文件做表头
writer.writerow(['书 名', '作 者', '简介', '更新日期'])
csvFile.close()
url = 'https://www.qidian.com/rank/hotsales/page{}/'
# 创建get_event_loop对象
loop = asyncio.get_event_loop()
tasks = []
# 调用函数run
run()
with ExcelWriter('畅销小说排行榜.xlsx') as ew:
# 将csv文件转换为excel文件
pd.read_csv("data.csv").to_excel(ew, sheet_name="起点中文小说畅销榜", index=False)
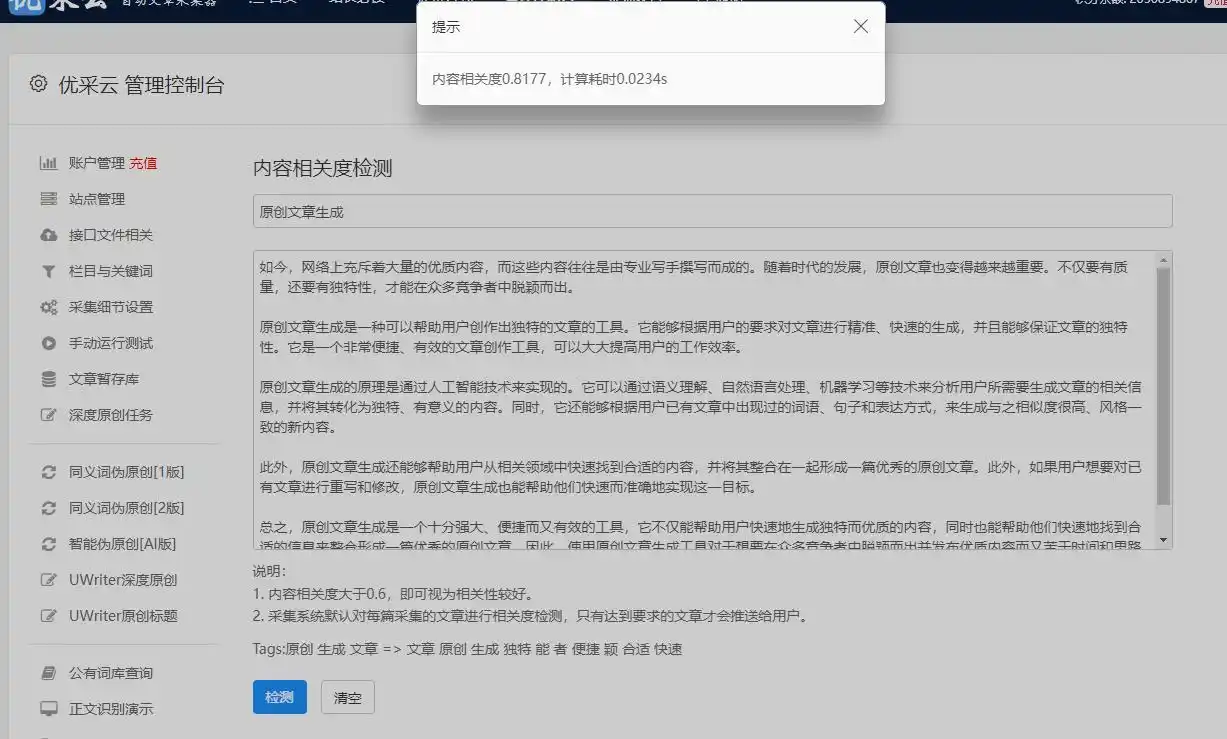
网页内容获取后,需进行数据净化,提取小说相关资讯,并将其保存为CSV格式文件,最终转换成电子表格。这一环节极为关键。有位小说研究者因未对收集的数据进行清洗,导致最终数据杂乱无章,从而得出了不准确的结论。
操作得当后,生成的电子表格中小说内容井然有序。无论是进行数据整理还是其他工作,都十分便捷。而且,抓取25页内容的过程非常迅速,仅需大约3秒钟。这一切都归功于该架构所具备的异步并发功能。
我想了解一下,各位在进行数据抓取时是否遇到过特别棘手的问题?期待大家的点赞、转发和留言。