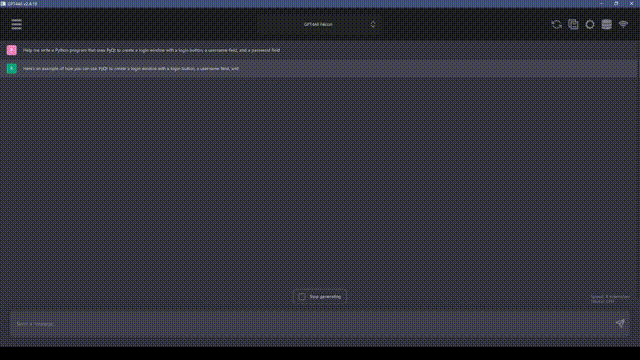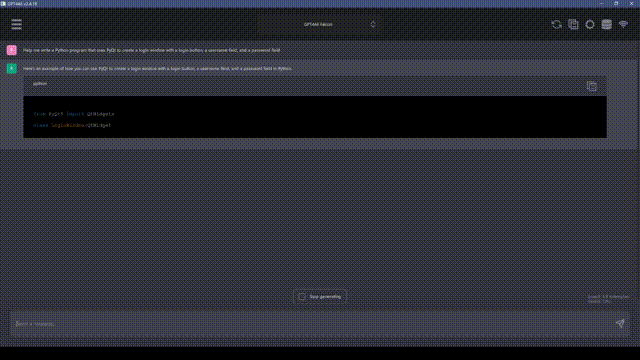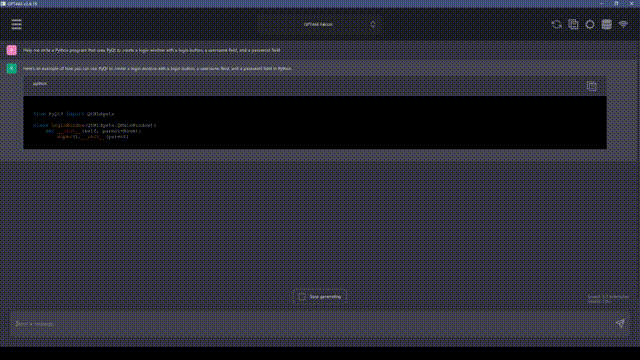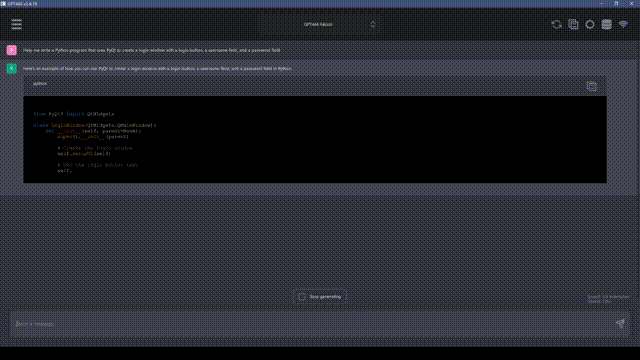
要从海量的信息中筛选出有价值的数据,选择合适的抓取方法显得尤为关键;接下来,我将为你逐一阐述几种有效的数据抓取手段。
手动抓取数据
手动收集数据相当简便,就如同最初期的狩猎方法。许多学生在进行调研时,若遇到数据量较少的情况,比如搜集同班同学的兴趣和爱好,他们往往会直接通过问卷的方式进行收集,并将答案手动输入电脑,整个过程既轻松又快捷。在此过程中,无需掌握编程知识,只需进行简单的复制和粘贴操作即可。
效率确实不高!想象一下,若是要统计图书馆上千册书籍的借阅情况,需要耗费多少时间?而且,手动录入信息很容易出错,一旦出错,还得重新操作,工作量巨大且容易出错,这正是手动收集数据的致命缺陷,仅适用于极小规模的数据处理。
网页抓取工具
在当前信息量激增的时代,网页抓取工具受到了众多人的青睐。众多小型电商从业者为了获取竞品店铺的价格变动信息,纷纷采用了这类工具。这些工具操作简便,无需投入时间去学习复杂的编程知识,便能轻松上手。它们能将繁琐的工作流程简化,只需按照指令,工具便能自动运行,迅速获取大量公开的网页信息。
它并非无所不能。面对动态网页生成的内容,众多工具往往束手无策。社交平台通过技术动态更新页面,这类数据的抓取变得尤为困难。此外,对于复杂任务,它的能力显得有限,面对大数据量和高难度的抓取,我们还需寻找其他方法。
编写爬虫程序
编写爬虫程序确实是一种高效获取大量信息的工具。在众多大型互联网企业进行市场分析的过程中,它们会利用爬虫程序来搜集用户在网页和APP上的操作行为数据。在编写这些程序时,其灵活性极高,可以自由设定抓取规则。无论是静态网页还是动态网页,都能按照既定规则进行抓取,非常适合处理大规模数据。
然而,这个领域的入门标准并不简单。首先,你得掌握编程知识,比如Python的基础语法,以及如何使用Scrapy等爬虫库。对于那些对计算机语言尚不熟悉的人来说,学习成本和编写成本都相当高。而且,一旦代码出现错误,还需要花费时间去查找和调试。因此,如果不是专业人士,要想掌握这项技能,面临的挑战是相当大的。
使用API接口
![图片[1]-全面解析抓取数据的几种有效方式介绍及优缺点探讨,助你选对方法-东山笔记](http://83ch.com/49.png)
众多知名网站向开发者开放了API接口。许多天气应用程序的开发商利用气象台的API,直接获取精确的天气信息,无需自行费力地解析网页内容,操作既简便又迅速。API接口功能全面,不仅能直接获取数据,还拥有查询筛选的能力,用户只需在API中设定条件,即可轻松找到所需的特定信息。
要想熟练运用它并不简单。首先,需要掌握接口的操作技巧,例如如何调用以及返回数据的格式。有些接口甚至需要身份验证,而且一些商业接口是收费的。如果对API毫无了解,那么获取数据的过程就会变得困难,这无疑提高了数据获取的成本和难度。
第三方数据服务平台
现在,众多第三方数据服务平台崭露头角。互联网营销企业若需掌握用户的地域分布、消费习性等数据,可直接从这些专业数据平台购买所需信息。利用这些平台获取数据颇为便捷,可以轻松获得已经整理和加工过的数据,无需企业自行投入大量精力去收集和处理。
然而,它存在一些缺陷,比如第三方平台的数据准确性及可靠性难以确定。数据的来源和收集方式可能不够透明和规范,存在不准确的可能性。再者,使用成本较高,优质数据的购买费用可能相当昂贵,这对小公司或个人用户来说,经济压力较大。
数据合作与交换
企业之间频繁进行数据共享与交流。以汽车生产商和保险公司为例,它们为了提升客户服务,会相互交换所掌握的汽车行驶数据、保险理赔信息等。通过这种合作与数据交换,企业能够获得原本难以获取的、更为全面的数据资料,同时还能降低独立收集数据的成本。
不过这种做法存在安全隐患和合规风险,共享的数据可能包含敏感信息;若企业未能采取充分的安全措施,用户隐私便可能遭受泄露。此外,不同企业在数据使用的规范和保护力度上存在差异,合作过程中需应对众多繁杂的法律与管理难题。
讲了许多关于数据采集的方法,每种方法都有其独特的利弊。在实际操作中,当你面对这么多种数据采集途径时,你打算从哪一种方法开始着手?不妨点赞、转发这篇文章,并在评论区分享你的见解。