你知道吗?存在一类名为爬虫的软件,它们可以在互联网上自动搜集信息。这类软件功能强大,能帮助我们发掘大量有价值的数据。现在,我们就来深入探讨一下这个话题。
爬虫简介
爬虫是通过编程技术构建的,主要功能是抓取和处理网络信息。在众多编程语言中,Python凭借其庞大的内置库资源,特别适合用于网络爬虫的开发,能够轻松实现各种功能。比如,在进行数据采集的项目时,运用Python编写爬虫可以迅速且高效地完成任务。
运用爬虫技术搜集信息,就像在广阔的信息海洋中精准捕捉到我们需要的“信息之鱼”。这种方法突破了传统人工收集信息的局限,极大地提高了我们的工作效率和科研进展速度。
爬虫用途
爬虫的作用非常丰富多样。它能协助搜索引擎在网络上搜集网页资料并构建索引,使得用户能够快速找到所需的信息,例如百度和谷歌就是通过这样的方式运作。除此之外,爬虫还能收集众多电商平台的商品资讯,为市场调研提供数据支撑。在广告筛选领域,爬虫通过捕捉网页上的广告资讯,实现了对广告的筛选与过滤。
在数据分析领域,爬虫的作用不可小觑。它能快速收集众多相关数据,这些数据为后续的分析和决策提供了坚实的支撑,因此,它成为了众多数据分析师强有力的助手。
爬虫架构
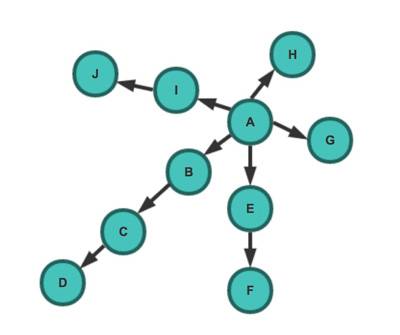
爬虫系统由调度器、URL管理者、网页抓取工具、网页解析模块以及应用软件五个核心部分构成。调度器相当于电脑的中央处理器,主要职能是协调各个模块的运作。在大型网络爬虫项目中,调度器需合理分配资源与任务,确保程序运行的高效性。
URL管理器承担着存储待抓取与已抓取网址的重任,目的是防止重复抓取和循环抓取现象的发生。实现这一功能有多种方式,比如利用内存、数据库或缓存数据库等,每种方法都适用于不同规模的网络爬虫任务。
网页下载器
![图片[1]-详细讲解Python中的爬虫:功能、架构及应用价值全解析-东山笔记](http://83ch.com/45.png)
网页下载器根据输入的网址进行操作,下载网页内容,并将其转换成字符串。官方提供的基础模块可以处理一般的网页下载任务,然而,若遇到需要登录验证或使用代理的服务页面,就需要采用特别的策略。而对于那些需要会员权限才能获取的网站信息,这些特别的技巧就显得尤为重要。
网页下载的第三方组件同样极具实用性,它们带来了更强大的功能,操作起来也更加便捷。这些组件是根据各种应用场景精心设计的,用户可以根据自己的实际需求来挑选合适的组件。
网页解析器
网页解析器能够解读网页上的文本,从中挑选出有价值的部分。正则表达式是常用的一种方法,操作起来相对简单,但面对结构繁杂的文档,它常常显得不够有力。特别是当网页的结构层层嵌套变得复杂时,正则表达式在提取信息方面就显现出它的局限性。
HTML的解析方法,包括html.parser本身以及如BeautifulSoup、lxml等第三方工具,普遍运用DOM树结构进行操作,这使得它们的功能更为全面,运行效率也更高。尤其是lxml,它具备处理XML和HTML文件的能力,因此在实际应用场景中,它的应用范围非常广泛。
爬虫框架及应用领域
常见的网络爬虫框架种类繁多,例如Grab,这是一个以Python和urllib2为技术核心的爬虫工具;Scrapy框架则依托于Twisted,尽管它暂时不兼容Python 3,但其功能相当强大,能够便捷地获取HTTP资源。除此之外,还有基于Flask的轻量级爬虫框架等。
爬虫应用广泛,其在网络爬虫领域发挥着至关重要的作用。借助Scrapy、BeautifulSoup、urllib等工具,只要遇到数据抓取的需求,爬虫一般都能应对自如。无论是进行舆情监测还是市场调研,爬虫都表现出了非凡的效能。
在运用爬虫进行操作时,你是否曾遭遇过一些挑战?若你觉得这篇内容对你有所启发,别忘了给它点赞,同时也欢迎你将它转发给更多人。