你是否有过手动复制网页表格信息的烦恼?借助爬虫技术,我们可以轻松高效地获取这些数据。快来了解一下这项技术
爬虫概述
爬虫软件能够自动搜集网络上的资讯,它犹如一位不知休憩的帮手,在浩瀚的互联网信息海洋中不断为你搜集资料。近年来,伴随着大数据技术的不断发展,爬虫软件的重要性愈发明显,其应用领域也在不断扩大。在金融、科研等多个行业中,爬虫软件能够快速获取大量数据,进而有效减少人力和时间的投入。
表格数据特点
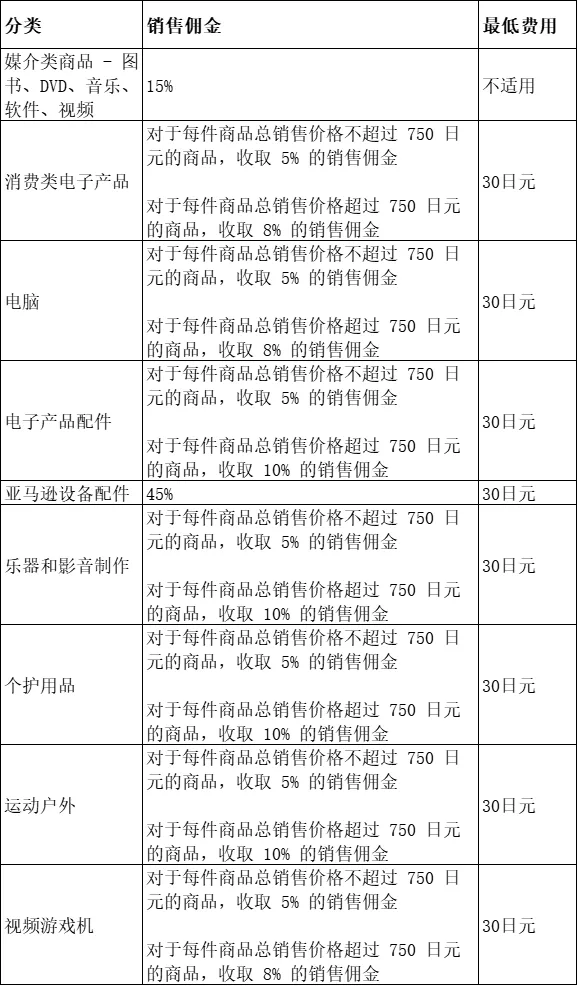
网页上的表格排列井然,行与列清晰可见,就像一列排列整齐的队伍。数据点之间相互联系,查阅和解读起来都很方便。财务报告和统计数据等资料通常以表格形式呈现,这让我们能快速抓住关键信息。
爬取工具介绍
Python的Request库使我们能够轻松执行HTTP请求,帮助我们获取网页的原始数据,仿佛为爬虫装备了快速捕捉信息的“锐利爪牙”。而且,BeautifulSoup工具宛如一位聪明的“解码者”,能够解析HTML和XML文档,精确地定位我们所需的表格内容。很多数据分析师都经常用它来处理复杂的网页结构。
from bs4 import BeautifulSoup
import requests
import csv
import bs4
#检查url地址
def check_link(url):
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
print('无法链接服务器!!!')
#爬取资源
def get_contents(ulist,rurl):
soup = BeautifulSoup(rurl,'lxml')
![图片[1]-Python爬虫如何爬取网页表格数据,这里有详细介绍-东山笔记](https://83ch.com/wp-content/themes/zibll/img/thumbnail-lg.svg)
trs = soup.find_all('tr')
for tr in trs:
ui = []
for td in tr:
ui.append(td.string)
ulist.append(ui)
#保存资源
def save_contents(urlist):
with open("D:/2016年中国企业500强排行榜.csv",'w') as f:
writer = csv.writer(f)
writer.writerow(['2016年中国企业500强排行榜'])
for i in range(len(urlist)):
writer.writerow([urlist[i][1],urlist[i][3],urlist[i][5]])
def main():
urli = []
url = "http://www.maigoo.com/news/463071.html"
rs = check_link(url)
get_contents(urli,rs)
save_contents(urli)
main()
爬取步骤详解
首先,我们要明确表格的具体位置,这需要通过分析网页源代码来识别表格的标识和属性,比如识别table标签作为表格内容的标记。在编写代码的过程中,要注意设置正确的请求头部和处理编码等细,否则可能会遇到获取数据的问题。一个有效的方法是利用开发者工具来检查网页的结构。
处理异常情况
网络连接不顺畅,网页还设置了反爬虫功能,这些都可能导致数据抓取失败。针对这些问题,我们可以实施重试机制,使用代理IP来绕过反爬虫的限制。同时,我们还可以调整数据抓取的速度,以减轻服务器的压力,从而提升数据抓取的成功率。
数据的后续利用
获取表格数据是起始环,随后我们对数据进行整理和深入挖掘。整理数据就是要去除干扰和重复内容,以保证数据的纯净和精确。数据整理完毕,我们就可以利用分析工具制作图表,随后对数据进行更深入的探究。比如,通过图表,我们可以直观地看到数据的变化走向。
获取网站表格内容是否很有帮助?在利用爬虫技术搜集表格资料时,你是否遭遇了一些难题?不妨点赞并交流你的心得,我们能在评论区深入探讨。